Turning 30,000 Arabic domains into a better crawl
This article is cross-posted from the Common Crawl Foundation’s blog.
If we want to improve what’s in our corpus, we need to know where to look. This is what the web-languages project is all about. Each month when we crawl, we don’t decide which pages to visit by looking at the whole internet top down. Instead, we crawl “bottom up”, starting from a list of seed web domains and exploring out from there. The web-languages project allows contributors to donate seed domains for their language, community or culture. We add these to our seed list, and over time, our crawl should become more diverse as we explore more regions of the web.
Earlier this year, researchers at the Qatar Computing Research Institute (QCRI) donated 30,000 domains from the Arabic-speaking world. These seeds had been enriched with human annotations of the overall quality of each domain, as well as labels and summaries of the content created using GPT-4o. My job then was to process the donated domains into a seed list we could use in future crawls.
We split this task into four questions:
- What can we learn from the human- and LLM-generated labels?
- What are the likely origin countries of the domains?
- Can we use the LLM-generated summaries to categorise the seeds?
- Are there domains which no longer contain Arabic content?
You can follow along with the analysis using the Jupyter notebook in the accompanying repo.
Understanding the human- and LLM-generated labels
The first stage of this work, curating and annotating the domain list, was carried out by researchers at QCRI. Creating the annotations was a substantial effort, taking about four months to complete. The original list of domains was extracted from 80 Common Crawl archives. Next, a team of ten native Arabic-speaking annotators from across the region each evaluated 3000 domains, based on a sample of 20 articles from each domain. The result was overall holistic scores for 30,000 unique domains, which overall covered 78% of the articles in the extracted corpus. To ensure quality, expert linguists independently annotated a random sample of 10% of the domains from each annotator, flagging work for revision if the inter-annotator agreement fell below 90%.
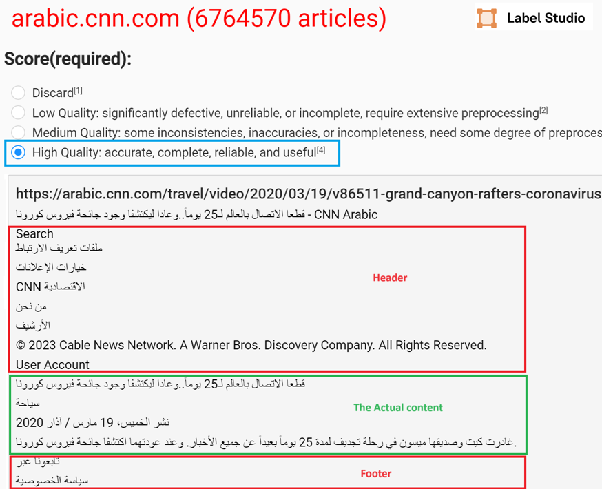
The human and the GPT-4o judgements used the same labels:
- Discard: Non-Arabic, pornographic, or hateful content.
- Low Quality: Significantly defective, unreliable, or incomplete text requiring extensive preprocessing.
- Medium Quality: Content with minor inconsistencies, inaccuracies, or incompleteness, requiring some degree of preprocessing.
- High Quality: Accurate, complete, reliable, and highly useful text.
The GPT-4o labels for the sampled pages in each domain were then summarised as “Accept” or “Reject”, based on the majority assessment.
When Common Crawl received the data, our first question was how reliable the LLM-generated content was compared to the human annotations. As a first test, we looked at how often the human and LLM-generated judgements agreed with each other. Results were promising, as shown in this heat map:
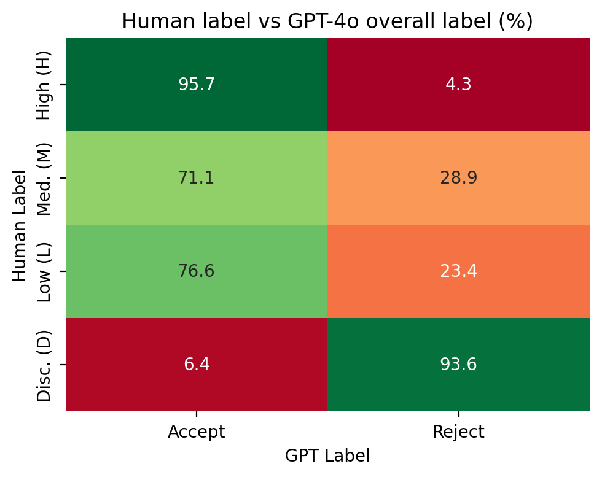
At the extremes, the human annotators and LLM judgements usually agreed: 95.7% of the domains rated as high quality by humans are judged acceptable by the LLM, and 93.6% of the domains marked to discard are rejected by the model as well. Interestingly, in the middle the LLM’s judgement is less clear: We would expect more of the domains annotated as low quality would be discarded by the LLM than those judged as medium quality, but in fact a slightly higher percentage of the medium quality domains are rejected than the low (28.9% versus 23.4%). This suggests that borderline content is more difficult for the LLM to judge consistently.
We also investigated how the LLM-generated themes and human annotations interacted. In the plot below, each row represents one of the top ten themes in the dataset. The colours show how the human annotators rated the quality of the pages under each theme as a percentage (e.g. green is high quality, red is discard).
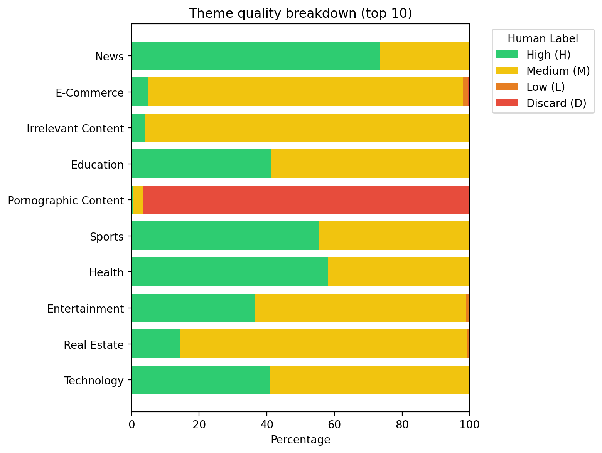
The LLM-generated themes and the human annotations of quality were assigned separately, so it is reassuring to see that themes we would expect to be higher quality (e.g. news) and themes we would expect to be lower quality (e.g. pornographic content) match the human annotations. Qualitative inspection of samples of domains from each category was also promising, with domains mostly matching their themes well.
Outcome: We discarded all domains marked as “Discard” by the human annotators, as well as those marked “Reject” by the LLM. Given that these seeds are going into the crawl, we preferred to be cautious and risk a false positive. Similarly, we also discarded the domains marked as low quality by the human annotators since these were few. We also removed any pages without GPT-generated themes since these seemed to be unreachable. This left 19,001 domains for further enrichment. Finally, we decided to trust the LLM-generated themes for further analysis, especially for the larger categories, because they seemed to correspond well to human judgements.
Finding likely origin countries
The seed list should contain entries from across the Arabic-speaking world, so that it represents the diversity of cultures and communities from that region. It makes sense then to label each donated domain with its country of origin where possible. The most straightforward way to do that is to look for the country code top-level domain (ccTLD) where present e.g. ‘.eg’ for Egypt, ‘.dz’ for Algeria. However, only about 15% of the domains contained a ccTLD, with the rest using generic TLDs like .com or .net. What’s more, the ccTLDs in the data didn’t necessarily belong to an Arabic-speaking country. Some of the surprises in the top 25 are explained by looking at their ccTLDs: Montenegro (.me, a common abbreviation for the Middle East), Poland (.pl, possibly used for Palestine as well as the official .ps), and Tuvalu (.tv, for television channels). Other countries have historical links with the Arabic-speaking world, such as France, Germany, and the Netherlands.
Aside from the ccTLD, many domains have clues to their country in the domain name itself e.g. www.jordan-hospital.com. As a quick way to find these domains, we built a dictionary of keywords for each country, including local names (e.g. misr/masr for Egypt), abbreviations (e.g. ksa for Saudi Arabia), capital cities for each country and the separate emirate names for the UAE. We then split the domains into sections separated by ., - or _, so saudi-lawyers.net became [saudi, lawyers, net], then searched each section for country keywords. About 24% of the domains had country-indicating keywords in the domain itself.
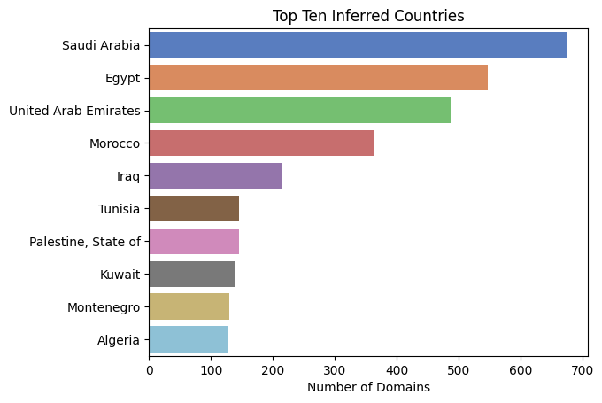
Outcome: We combined the country predictions from the ccTLDs and the domain names themselves, trusting the country code derived from the ccTLD over that from the domain name in case of a conflict. 25% of the domains were enriched with an associated country, and nine out of ten of most common derived countries are found in the Arab world (Montenegro, .me, is ninth). There are likely some false positives, but the inferred country information seems good enough to be useful.
Categorising the seeds with LLM-generated themes
As previously mentioned, the researchers from QCRI enriched each donated domain with a list of themes from five random articles from the domain, derived using GPT-4o. Based on the initial analysis, the themes look useful, but since they are from five random pages in the domain, they’re not always consistent. For example, the entries for www.jordan-hospital.com all concern healthcare:
'Healthcare - Hospital Information| Healthcare - Hospital Staff and Specialties| Healthcare - Medical Specialties| Healthcare - Medical Services| Healthcare - Medical News'
On the other hand, the entries for ar.m.wikipedia.org reference a mixture of articles:
'Biography - Sports| Sports - Facilities| History - Conflicts| Food - Culinary History| History - Conflicts'
We decided to deal with this by extracting the main theme from each element in the list (the part before the dash), and then counting up the most common words or two-word phrases for each domain overall. This wouldn’t capture the most diverse sites (like Wikipedia in the example above), but would serve as a good rule of thumb. The top themes extracted using this method looked reasonable, with the most common being e-commerce, news, and sports.
For the final categorisation, we labelled key themes iteratively using a combination of the derived top theme and information in the domain. For example, we were conservative labelling government sites, only applying the label to those with .gov in the suffix. For news, we used the derived top theme, but also looked for the word ‘news’ in the domain. For e-commerce, we looked for a range of keywords in the top theme like “advert”, “business” or “product”. These decisions were based on multiple rounds of data inspection as more domains were categorised into themes. For more detail, step three in the notebook walks through the process.
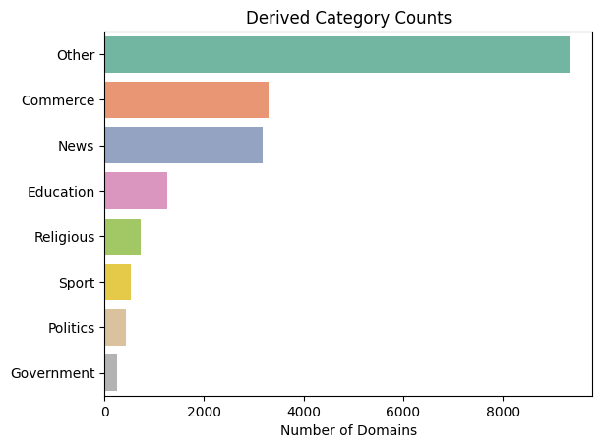
Outcome: We labelled the domains using eight categories: Commerce, News, Education, Religious, Sport, Politics, Government and Other. 49% of the domains were assigned to the Other category, with the rest assigned a more specific category. There were some large top themes left outside of the categories (e.g. health), but we wanted to be relatively conservative and only include relatively homogenous categories.
Checking domains for Arabic content
Domains on the web are not static, but rather their content and owners are likely to change over time. The point of this seed list is to prioritise Arabic content, so we decided to check that for the domains present in our most recent crawls, their content is still in Arabic.
Up until now, we used Python for the analysis, but to check against the most recent crawls, we switched to using AWS Athena to query the URL index. For ease of query, we created a table of the reversed domains that we wanted to query (arabic_seeds). We then ran the following query to bring back the language predictions for each captured page in each domain, if it’s found in the most recent crawl (CC-MAIN-2026-21):
SELECT
s.reversed_host,
c.language_counts
FROM "ccindex"."arabic_seeds" s
LEFT JOIN (
SELECT
url_host_name_reversed,
histogram(language) as language_counts
FROM "ccindex"."ccindex",
UNNEST(split(content_languages, ',')) AS t (language)
WHERE crawl = 'CC-MAIN-2026-21'
AND subset = 'warc'
GROUP BY url_host_name_reversed
) c ON s.reversed_host = c.url_host_name_reversed
This query brings back the language predictions for all the pages for the seed domains found in the crawl. It then groups by the domain again, counting how many times each language prediction appears for all the pages across the domain. This count is rough, since a page can have multiple language predictions, but it indicates if there is likely Arabic content in the domain.
For the domains not found in the most recent crawl, we searched the next most recent crawl (CC-MAIN-2026-17), and then the next for any still without matches (CC-MAIN-2026-12). We filtered out any pages found where the language predictions did not contain Arabic.
Outcome: 8772 or 46% of the domains were enriched with language information from the three most recent crawls. 801 of these did not contain detected Arabic and so were filtered out. This left 18,200 domains remaining, 7971 of which have language information (43.8%).
Wrap up
In this analysis, we started with a list of 30,000 Arabic seeds with human- and LLM annotations, and ended up with a list of 18,200 domains enriched with location and category information. These enriched seeds will be added to the web-languages project and used in future crawls. Over time, this should increase the amount of Arabic content in Common Crawl’s corpus as we explore more of the sites connected to these seeds.
This repository contains all the code and data used for the analysis in this blogpost. Thank you to Hamdy S. Hussein, Dr. Kareem M. Darwish and Dr. Mohamed Ahmed Yassin Eltabakh of the Qatar Computing Research Institute for providing the initial seed list, quality annotations and exploratory visualisations. These artefacts were created as part of the Fanar Project, an Arabic generative AI platform.